
Autor: Kavita Char, director de marketing de producto
El Internet de las cosas está explotando. Los dispositivos están conectados y comunicándose entre sí, gracias a una conectividad ubicua por cable e inalámbrica. Esta hiperconectividad permite la recopilación de cantidades masivas de datos que pueden recopilarse, analizarse y utilizarse para tomar decisiones inteligentes. La capacidad de extraer conocimientos de los datos y tomar decisiones autónomas basadas en estos conocimientos es la esencia de la Inteligencia Artificial (IA). La combinación de IA e IoT o Inteligencia Artificial de las Cosas (AIoT), permite la creación de dispositivos “inteligentes” que aprenden de los datos y toman decisiones sin intervención humana.
Hay varios impulsores de esta tendencia a desarrollar inteligencia en dispositivos perimetrales:
- La toma de decisiones en el Edge, reduce la latencia y el costo asociados con la conectividad en la nube y hace posible la operación en tiempo real
- La falta de ancho de banda en conexiones a la nube impulsa la computación y la toma de decisiones en los dispositivos perimetrales.
- La seguridad es una consideración clave: los requisitos de privacidad y confidencialidad de los datos impulsan la necesidad de procesar y almacenar datos en el propio dispositivo.
Por lo tanto, la IA en el Edge ofrece ventajas de autonomía, menor latencia, menor consumo de energía, menores requisitos de ancho de banda, menores costos y mayor seguridad, todo lo cual la hace más atractiva para nuevas aplicaciones y casos de uso emergentes.
AIoT ha abierto nuevos mercados para las MCU, permitiendo un número cada vez mayor de nuevas aplicaciones y casos de uso que pueden usar MCU combinadas con alguna forma de aceleración de IA para facilitar el control inteligente en dispositivos Edge y terminales. Estas MCU habilitadas para IA proporcionan una combinación única de capacidad DSP para computación y aprendizaje automático (ML) para inferencia y se utilizan en aplicaciones tan diversas como detección de palabras clave, fusión de sensores y análisis de vibraciones. Las MCU de mayor rendimiento permiten aplicaciones más complejas en visión e imágenes, como reconocimiento facial, análisis de huellas dactilares y detección de objetos.
Las redes neuronales se utilizan en aplicaciones de IA/ML, como clasificación de imágenes, detección de personas y reconocimiento de voz. Estos son componentes básicos que se utilizan en la implementación de algoritmos de aprendizaje automático y hacen un uso extensivo de operaciones de álgebra lineal, como productos escalares y multiplicaciones de matrices, para el procesamiento de inferencias, entrenamiento de redes y actualizaciones de pesos. Como se puede imaginar, incorporar IA en productos de vanguardia requiere una capacidad informática significativa en los procesadores. Los diseñadores de estas nuevas aplicaciones de IA emergentes deben abordar las demandas de mayor rendimiento, mayor memoria y menor consumo, todo ello manteniendo los costos bajos.
En el pasado, esto era competencia de las GPU y MPU con potentes núcleos de CPU, grandes recursos de memoria y conectividad en la nube para análisis. Más recientemente, hay aceleradores de IA disponibles que pueden descargar esta tarea de la CPU principal. Otras aplicaciones informáticas de vanguardia, como el procesamiento de audio o imágenes, requieren soporte para operaciones rápidas de acumulación múltiple. A menudo, los diseñadores optaron por agregar un DSP al sistema para manejar el procesamiento de señales y las tareas computacionales. Todas estas opciones proporcionan el alto rendimiento requerido, pero añaden un costo significativo al sistema y tienden a consumir más energía y, por lo tanto, no son adecuadas para dispositivos finales de bajo consumo y bajo costo.
¿Cómo pueden las MCU llenar este vacío?
La disponibilidad de MCUs de mayor rendimiento permite que el AIoT de vanguardia de bajo costo y bajo consumo se convierta en una realidad. AIoT está habilitado por una mayor capacidad de procesamiento de las MCUs recientes, así como por modelos de redes neuronales ligeras que son más adecuadas para las MCU con recursos limitados utilizadas en estos dispositivos de uso final. La IA en dispositivos IoT basados en MCUs permite la toma de decisiones en tiempo real y una respuesta más rápida a los eventos, y también ofrece las ventajas de menores requisitos de ancho de banda, menor potencia, menor latencia, menores costos y mayor seguridad que las MPU o DSP. Las MCUs también ofrecen tiempos de activación más rápidos, lo que permite realizar inferencias más rápidamente y reducir el consumo de energía, así como una mayor integración con la memoria y los periféricos para ayudar a reducir los costos generales del sistema para aplicaciones sensibles a los costos.
Las MCUs basadas en Cortex-M4/M33 pueden realizar las tareas y casos de uso de IA más simples, como la detección de palabras clave y tareas de mantenimiento predictivo con menores necesidades de rendimiento. Sin embargo, cuando se trata de casos de uso más complejos, como las tareas de visión con IA (detección de objetos, estimación de pose, clasificación de imágenes) o la IA de voz (reconocimiento de voz, PNL), se requiere un procesador más potente. El núcleo Cortex-M7 más antiguo puede realizar algunas de estas tareas, pero el rendimiento de inferencia es bajo, normalmente sólo en el rango de 2 a 4 fps.
Lo que se necesita es un microcontrolador de mayor rendimiento con aceleración de IA.
Presentamos las MCU con IA de alto rendimiento de la serie RA8
Las nuevas MCUs de la serie RA8 cuentan con un núcleo Arm Cortex-M85 basado en la arquitectura Arm v8.1M y pipeline superescalar de 7 etapas, brindan la aceleración adicional necesaria para las tareas de procesamiento de señales o procesamiento de redes neuronales con uso intensivo de cómputo.
El Cortex-M85 es el núcleo Cortex-M de mayor rendimiento y viene equipado con Helium™, la extensión vectorial de perfil M (MVE) de Arm introducida con la arquitectura Arm v8.1M. Helium es una extensión del conjunto de instrucciones de procesamiento vectorial de datos múltiples de instrucción única (SIMD) que puede mejorar el rendimiento al procesar múltiples elementos de datos con una sola instrucción, como acumulaciones multiplicativas repetitivas sobre múltiples datos. Helium acelera significativamente las capacidades de procesamiento de señales y aprendizaje automático en dispositivos MCU con recursos limitados y permite una aceleración sin precedentes de 4x en tareas de ML y 3x de aceleración en tareas de DSP en comparación con el núcleo Cortex-M7 anterior. Combinadas con una gran memoria, seguridad avanzada y un amplio conjunto de periféricos e interfaces externas, las MCU RA8 son ideales para aplicaciones de inteligencia artificial de voz y visión, así como para aplicaciones informáticas intensivas que requieren soporte de procesamiento de señales, como procesamiento de audio, decodificación JPEG y control de motores.
¿Qué permiten las MCU RA8 con Helium?
El aumento del rendimiento de Helium se logra mediante el procesamiento de amplios registros vectoriales de 128 bits que pueden contener múltiples elementos de datos (SIMD) con una sola instrucción. Es posible que varias instrucciones se superpongan en la etapa de ejecución de la canalización. El Cortex-M85 es un núcleo de CPU de doble pulso y puede procesar dos palabras de datos de 32 bits en un ciclo de reloj, como se muestra en la Figura 1. Una operación de multiplicación y acumulación requiere una carga de la memoria a un registro vectorial seguida de una acumulación de multiplicación, lo que puede ocurrir al mismo tiempo que se cargan los siguientes datos desde la memoria. La superposición de cargas y multiplicaciones permite que la CPU tenga el doble de rendimiento que un procesador escalar equivalente sin penalizaciones de área y energía.
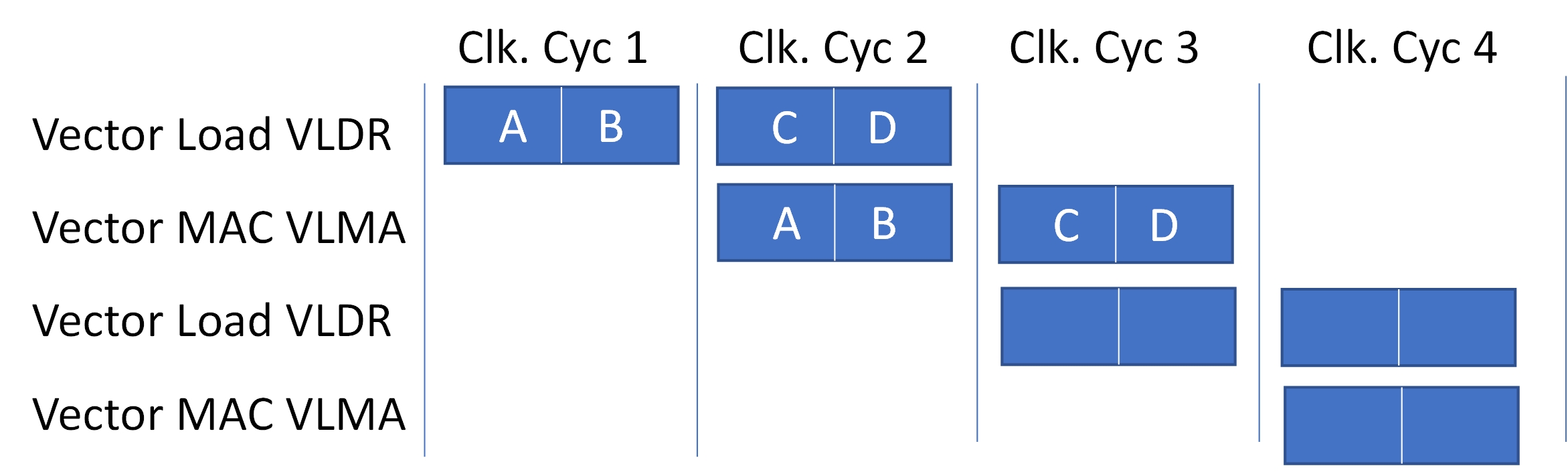
Figura 1: CM85 es una CPU de doble pulso, lo que significa que se pueden procesar dos palabras de 32 bits por ciclo de reloj
Helium presenta 150 nuevas instrucciones escalares y vectoriales para la aceleración del procesamiento de señales y el aprendizaje automático, que incluyen:
- Extensión de ramal de bajo costo (LOBE) para operaciones optimizadas de ramal y bucle y reducción de penalizaciones de ramal
- Predicción de ramas que permite la ejecución condicional de cada rama en un vector, lo que permite una vectorización eficiente de código condicional complejo
- Instrucciones vectoriales de recopilación, carga y almacenamiento de dispersión para lecturas y escrituras en ubicaciones de memoria no contiguas, útiles en la implementación de buffers circulares que se utilizan ampliamente en la implementación de filtros FIR en aplicaciones DSP.
- Operaciones aritméticas con números complejos como sumar, multiplicar y rotar utilizadas en algoritmos DSP
- Funciones DSP como buffers circulares para implementación de filtros FIR, direccionamiento de bits invertidos para implementaciones FFT y conversión de formato en procesamiento de imágenes y video con instrucciones de entrelazado y desintercalado.
- Matemática polinomial que admite la aritmética de campos finitos utilizada en algoritmos criptográficos y corrección de errores
- Soporte nativo para datos enteros de punto fijo de 8, 16 y 32 bits utilizados en procesamiento de audio/imagen y aprendizaje automático y datos de punto flotante de precisión media, simple y dual utilizados en procesamiento de señales.
- Rendimiento de multiplicación-acumulación (MAC) mejorado que admite dos MAC/ciclo de 32 bits*32 bits, cuatro MAC/ciclo de 16 bits*16 bits y ocho MAC de 8 bits*8 bits por ciclo de reloj
Estas características hacen que una MCU dotada con Helium sea particularmente adecuada para tareas de IA/ML y estilo DSP sin un DSP adicional o un acelerador de IA de hardware en el sistema y también reduce los costos y el consumo de energía.
Aplicación de gráficos y IA Vision con MCU RA8D1
Renesas ha demostrado con éxito esta mejora del rendimiento con Helium, en algunos casos de uso de IA/ML, mostrando una mejora significativa con respecto a una MCU Cortex-M7: más de 3,6 veces en algunos casos.
Una de esas aplicaciones es una aplicación de IA para detección de personas desarrollada en colaboración con Plumerai, un proveedor líder de soluciones de IA en el campo de la visión. Basada en la MCU RA8D1, la solución de IA de detección de personas basada en cámaras ha sido adaptada y optimizada para el núcleo Arm Cortex-M85 habilitado para Helium, demostrando con éxito tanto el rendimiento del núcleo CM85 y Helium como las capacidades gráficas del RA8D1. dispositivos.
Acelerada con Helium, la aplicación logra un aumento de rendimiento 3,6 veces mayor que el núcleo Cortex-M7 y una velocidad de fotogramas de 13,6 fps, lo que supone un rendimiento sólido para una MCU sin aceleración de hardware. La plataforma de demostración, captura imágenes en vivo desde una cámara basada en sensor de imagen OV7740 con una resolución de 640×480 y presenta los resultados de la detección en una pantalla LCD adjunta de 800×480. El software de detección de personas detecta y rastrea a cada persona dentro del marco de la cámara, incluso si está parcialmente ocluida, y muestra cuadros delimitadores dibujados alrededor de cada persona detectada superpuestos en la pantalla de la cámara en vivo.

Figura 2: Plataforma de demostración de IA de detección de personas de Renesas, presentada en Embedded World 2023
El software Plumerai People Detection utiliza una red neuronal convolucional con múltiples capas, entrenada con más de 32 millones de imágenes etiquetadas. Las capas que representan la mayor parte de la latencia total son las aceleradas por Helium, como Conv2D y las capas completamente conectadas, así como las capas de convolución profunda y convolución de transposición.
El módulo de la cámara proporciona imágenes en formato YUV422 que se convierte al formato RGB565 para mostrarlas en la pantalla LCD. Luego, el motor de gráficos 2D integrado en el RA8D1 cambia el tamaño y convierte el RGB565 a ABGR8888 con una resolución de 256×192, para su entrada a la red neuronal. El software de detección de personas se ejecuta en el núcleo Cortex-M85, luego convierte el formato ARBG8888 al formato de entrada del modelo de red neuronal y ejecuta la función de inferencia de detección de personas. Las funciones de dibujo que utilizan el motor de dibujo 2D del RA8D1 se utilizan para representar la entrada de la cámara en la pantalla LCD y también para dibujar cuadros delimitadores alrededor de las personas detectadas y presentar la velocidad de fotogramas. El software de detección de personas utiliza aproximadamente 1,2 MB de memoria flash y 320 KB de SRAM, incluida la memoria para la imagen de entrada ABGR8888 de 256×192.
Se realizó una evaluación comparativa para comparar la latencia de la solución de detección de personas de Plumerai, así como la misma red neuronal que se ejecuta con TFMicro con los núcleos CMSIS-NN de Arm. Además, para Cortex-M85, también se comparó el rendimiento de ambas soluciones con el helio (MVE) desactivado. Estos datos de referencia muestran un rendimiento de inferencia pura y no incluyen la latencia para las funciones gráficas, como las conversiones de formato de imagen.
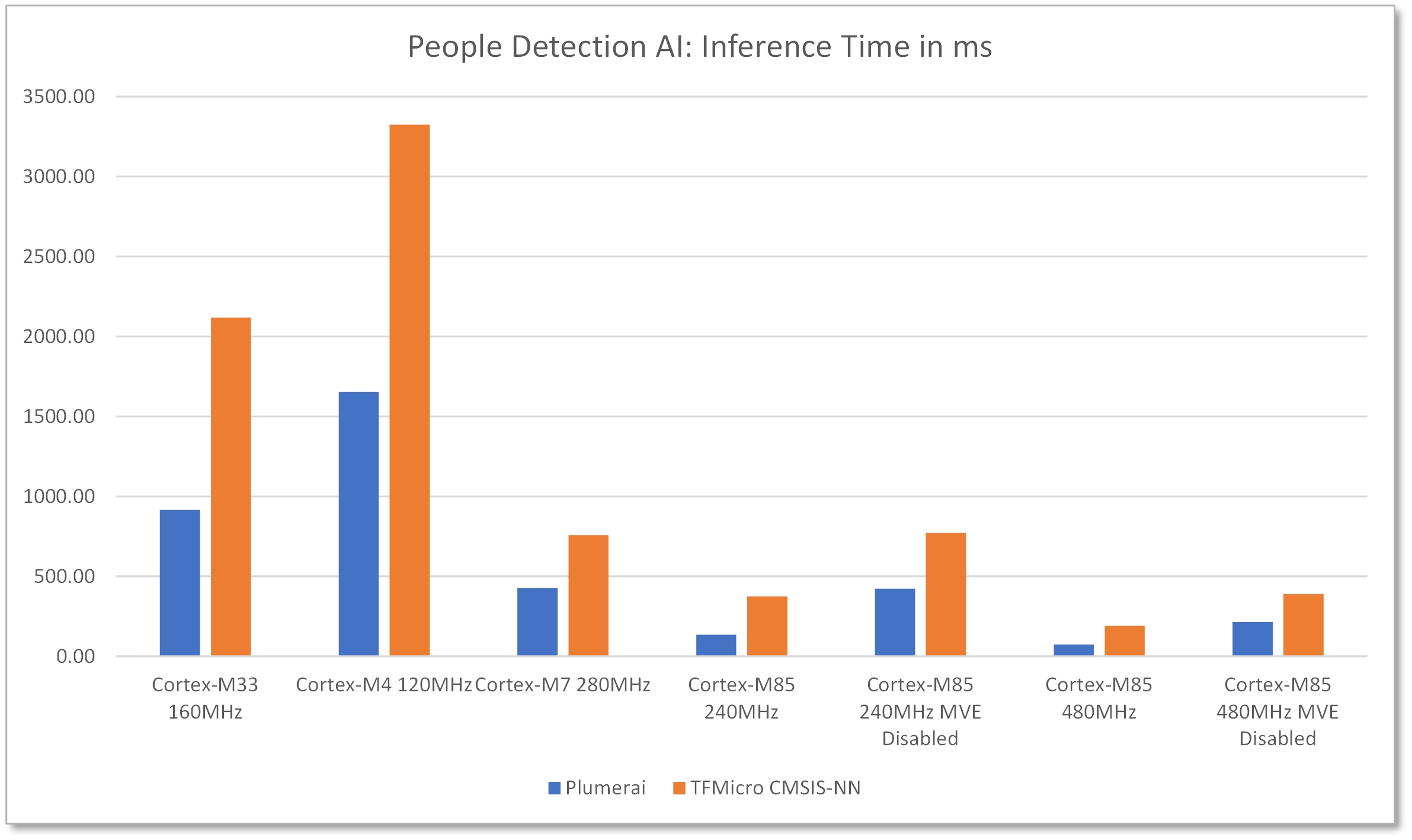
Figura 3: La demostración de detección de personas de Renesas demostró una mejora del rendimiento de 3,6 veces con respecto al núcleo Cortex-M7
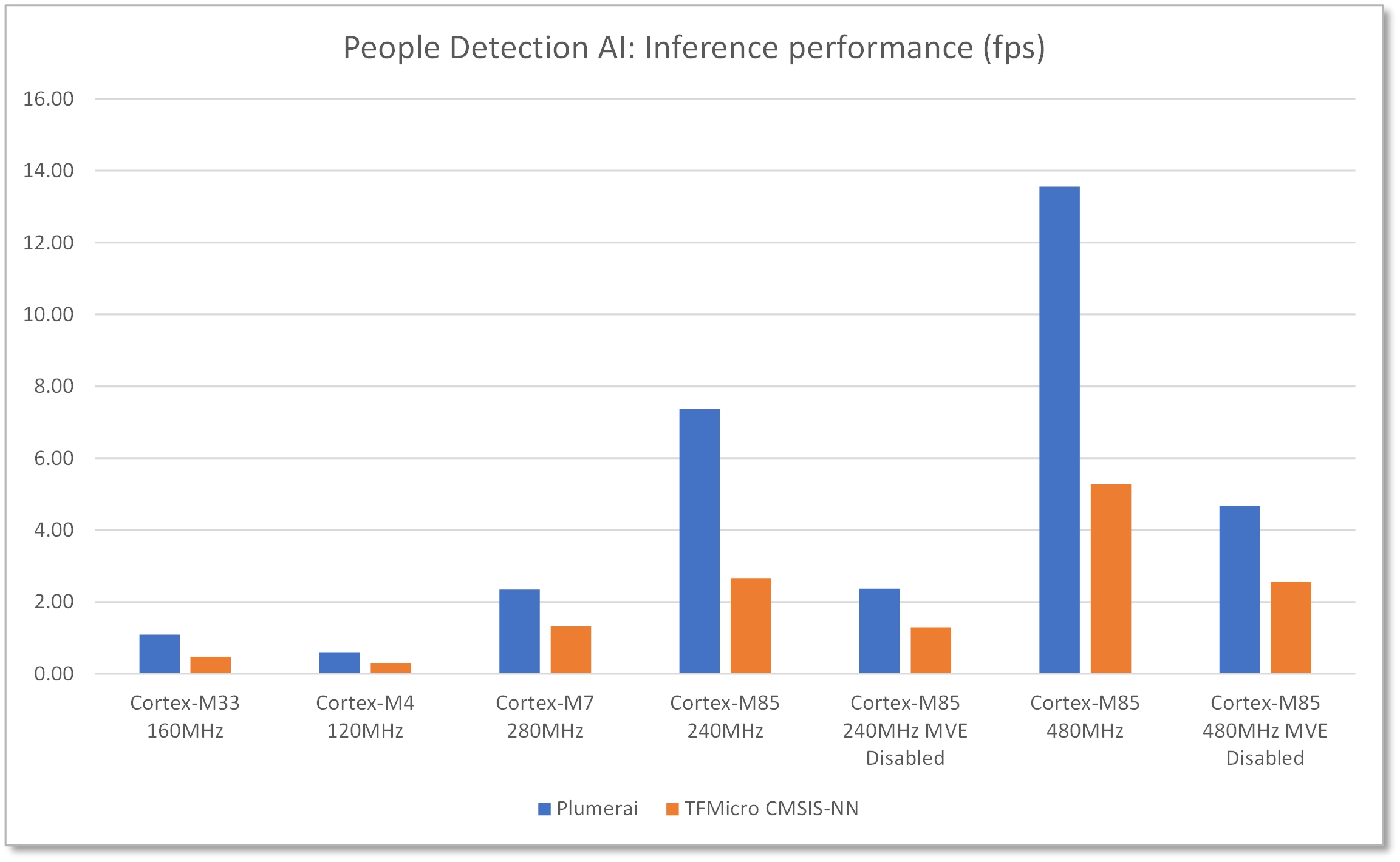
Figura 4: Rendimiento de inferencia de 13,6 fps a 480 MHz usando RA8D1 con Helium habilitado
Esta aplicación hace un uso óptimo de todos los recursos disponibles en el RA8D1: el alto rendimiento de 480 MHz, Helium para la aceleración de la red neuronal, una gran FLASH y SRAM para el almacenamiento de los datos del modelo y las activaciones de entrada, así como la cámara para la captura e introducción de imágenes/vídeo y la pantalla para mostrar los resultados de la detección.
Aplicación de voz AI con MCU RA8M1
Otra aplicación de este tipo es un caso de uso de reconocimiento de comandos de voz que se ejecuta en el RA8M1 e implementa una red neuronal profunda (DNN) que está entrenada con miles de voces diversas y admite más de 40 idiomas. Esta aplicación de voz presenta una mejora con respecto a la simple detección de palabras clave y admite una forma modificada de comprensión del lenguaje natural (NLU) que no depende solo de la palabra o frase de comando, sino que busca la intención. Esto permite el uso de un lenguaje más natural sin tener que recordar palabras o frases clave exactas.
La implementación de voz utiliza las instrucciones SIMD disponibles en el núcleo Cortex-M85 con helio. RA8M1 es una opción natural para este tipo de soluciones de inteligencia artificial de voz con su gran memoria, soporte para adquisición de audio y, sobre todo, el alto rendimiento y la aceleración de ML habilitada por el núcleo Cortex-M85 y Helium. Incluso la implementación preliminar de esta solución con y sin Helium demuestra una mejora del rendimiento de inferencia de más del doble con respecto a la MCU basada en Cortex-M7, como se muestra en la Figura 5.
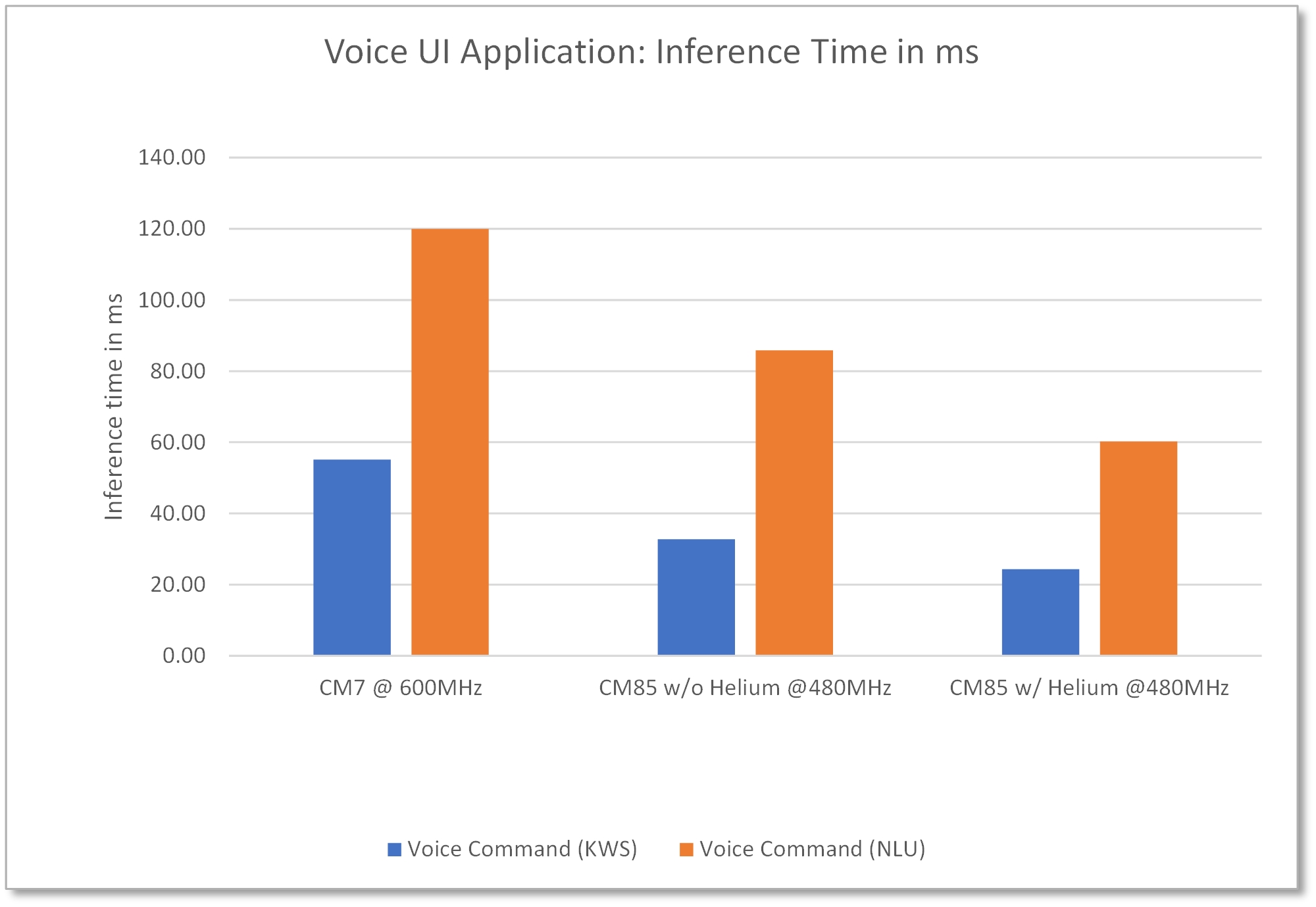
Figura 5: Aplicación de voz con AI en la MCU RA8M1 demuestra mejoras de rendimiento del CM85 respecto al CM7, sin y con Helium
Como es evidente, las MCU RA8 con Helium pueden mejorar significativamente el rendimiento de la red neuronal sin necesidad de aceleración de hardware adicional, proporcionando así una opción de bajo costo y bajo consumo de energía para la implementación de casos de uso más simples de inteligencia artificial y aprendizaje automático.
Referencias
En este artículo se hace referencia a los siguientes recursos:
- “Tecnología Arm® Helium™, extensión vectorial de perfil M (MVE) para procesadores Arm® Cortex®-M”, por Jon Marsh, Arm
- “Introducción a la arquitectura Armv8.1-M” Por Joseph Yiu, Arm, febrero de 2019
- Demostración de detección de personas Plumerai en MCU Renesas RA8D1




