Autor: Robert Perkel
Introducción
Los periféricos con lógica y flexibilidad integrados mejoran las aplicaciones al reducir el tamaño del código, disminuir el consumo y mejorar el rendimiento del sistema gracias a la implementación de lógica discreta y/o la conexión con otros periféricos.
Los periféricos de hardware integrados son bien conocidos por su capacidad para disminuir el consumo, mejorar el rendimiento, potenciar las capacidades del dispositivo y reducir el tamaño del código. Estos periféricos se suministran en diversos tipos de dispositivos, desde amplificadores operacionales y convertidores A/D (ADC) mejorados hasta moduladores de anchura de pulso (PWM) y temporizadores universales (UTMR). Entre los periféricos más potentes de este tipo se encuentran los que pueden incorporar lógica discreta o se pueden conectar a otros periféricos. Este artículo trata los periféricos CLC (Configurable Logic Cell), CCL (Configurable Custom Logic), EVSYS (Event System) y puerto SR (Signal Routing), y cómo se pueden utilizar para añadir valor a su diseño.
CLC / CCL
Los periféricos CLC (Configurable Logic Cell) y CCL (Configurable Custom Logic) son tablas de consulta programables, de modo que cada una de ellas equivale a una sola celda de una FPGA. La función lógica configurada dentro de cada periférico se define en el tiempo de ejecución. El periférico CLC/CCL puede funcionar de manera independiente respecto a la CPU, lo cual permite sustituir los chips lógicos discretos en el diseño. En cuanto a la diferencia entre un CLC y un CCL su implementación es muy similar: el CLC es específico para microcontroladores PIC® mientras que el CCL es específico para microcontroladores AVR®. El funcionamiento básico de ambos periféricos es el mismo.
Botones e interruptores para eliminación de rebote
Una de las aplicaciones más habituales para los CLC/CCL consiste en eliminar el rebote a nivel de hardware junto con un temporizador/oscilador. La Nota de Aplicación 2805 (AN2805) analiza tres formas de eliminación de rebote con CLC. De las tres, las dos versiones con CLC logran un buen equilibrio entre uso de recursos de hardware y rendimiento. El código fuente para las tres versiones está disponible en Github.
Para implementar el eliminador de rebote, uno de los CLC se configura como un biestable D para fijar el valor del botón o el interruptor. El segundo CLC retiene con AND lógicos el valor procedente de la etapa previa con la entrada directa y fija el valor resultante. La fuente de reloj para ambos biestables es una fuente de reloj de baja frecuencia generada por un temporizador u oscilador en el dispositivo. La siguiente figura indica cómo se lleva a cabo.
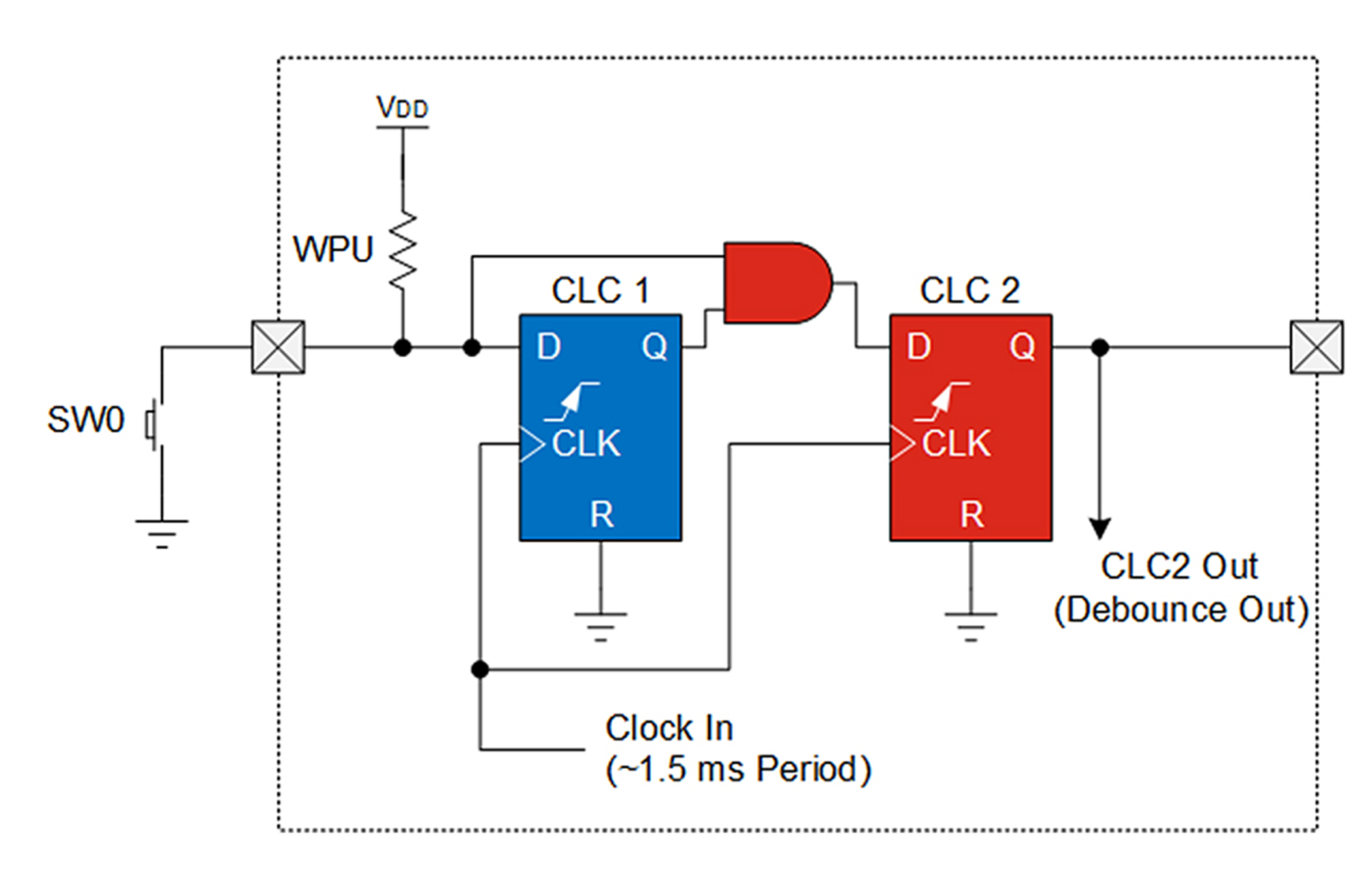
Figura 1. Eliminación de rebote con dos CLC.
Para los CCL en microcontroladores AVR resulta aún más sencillo. Los CCL contienen una opción de filtrado de entrada que realiza el mismo filtrado en dos ciclos que se implementaba en los CLC. Además, los CCL pueden obtener la señal de reloj de un oscilador de 1 kHz que es lo bastante lento como para eliminar el rebote.
Decodificación de cuadratura
Otra aplicación de los CLC es la decodificación de cuadratura. Los codificadores incrementales de cuadratura generan dos ondas cuadradas en las que una fase está 90 grados por delante de la otra. La cantidad de rotación viene determinada por el número de formas de onda, mientras que la fase de la forma de onda indica la dirección. La siguiente imagen ofrece un ejemplo de señal codificada de cuadratura.
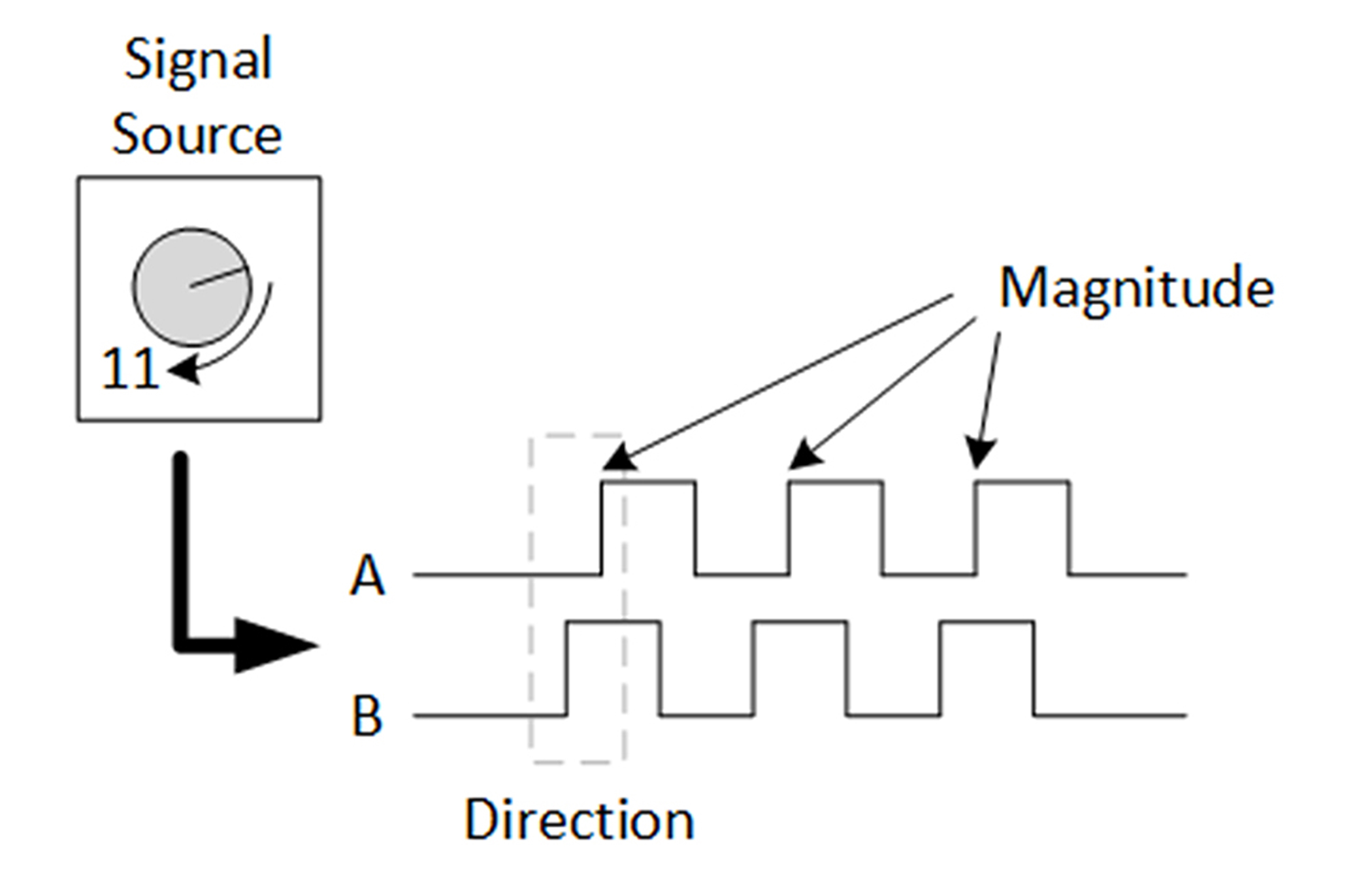
Figura 2. Ejemplo de forma de onda de cuadratura.
Para decodificarla, los CLC convierten esta forma de onda en dos salidas, representados con pulsos en el sentido de las agujas del reloj y en el sentido opuesto a las agujas del reloj. Dos temporizadores integrados en el microcontrolador cuentan el número de pulsos recibidos. Cuando el microcontrolador necesita conocer la variación neta de la posición solo hay que hacer unos sencillos cálculos matemáticos a partir del recuento de cada temporizador para obtener la variación neta desde la última lectura.
Event System
El sistema de eventos o Event System (EVSYS) está diseñado para seleccionar una señal de salida procedente de otro periférico y enviarla a otro u otros periféricos internos del microcontrolador. Esta interconectividad se puede realizar con independencia de la CPU, lo cual reduce el consumo en modo dormido o de reposo y mejora el rendimiento. EVSYS solo está disponible en microcontroladores AVR.
Puerto SR
En los microcontroladores PIC existe un periférico denominado puerto SR (Signal Routing). El puerto SR es una estructura parecida a un puerto E/S de salida pero integrado. Se puede utilizar software para establecer o borrar manualmente los bits que contiene, como un registro de salida de E/S convencional, pero también se encarga de las señales de salida del periférico y del registro de desplazamiento.
El puerto SR también funciona bien con la función PPS (Peripheral Pin Select) disponible en los microcontroladores PIC. PPS ofrece al diseñador la flexibilidad de asignar E/S para mover las señales de E/S digitales a diferentes patillas del microcontrolador. De forma parecida, PPS permite que los periféricos seleccionen cada “patilla” del puerto SR como entrada. De este modo es posible construir y controlar máquinas de estado avanzadas con este periférico.
Selección de señal en el dispositivo
Una posible aplicación del puerto SR y CLC es la implementación de un multiplexor de selección de señal interno que se podría utilizar para autocomprobación interna o para seleccionar una de las N señales a procesar. Para llevarlo a cabo se utiliza un CLC para crear un multiplexor 2:1. También se puede recurrir a un multiplexor 4:1 pero utiliza tres CLC y dos bits del puerto SR. Para controlar el multiplexor se usa un bit del puerto SR como línea de selección. La siguiente figura muestra su implementación lógica.
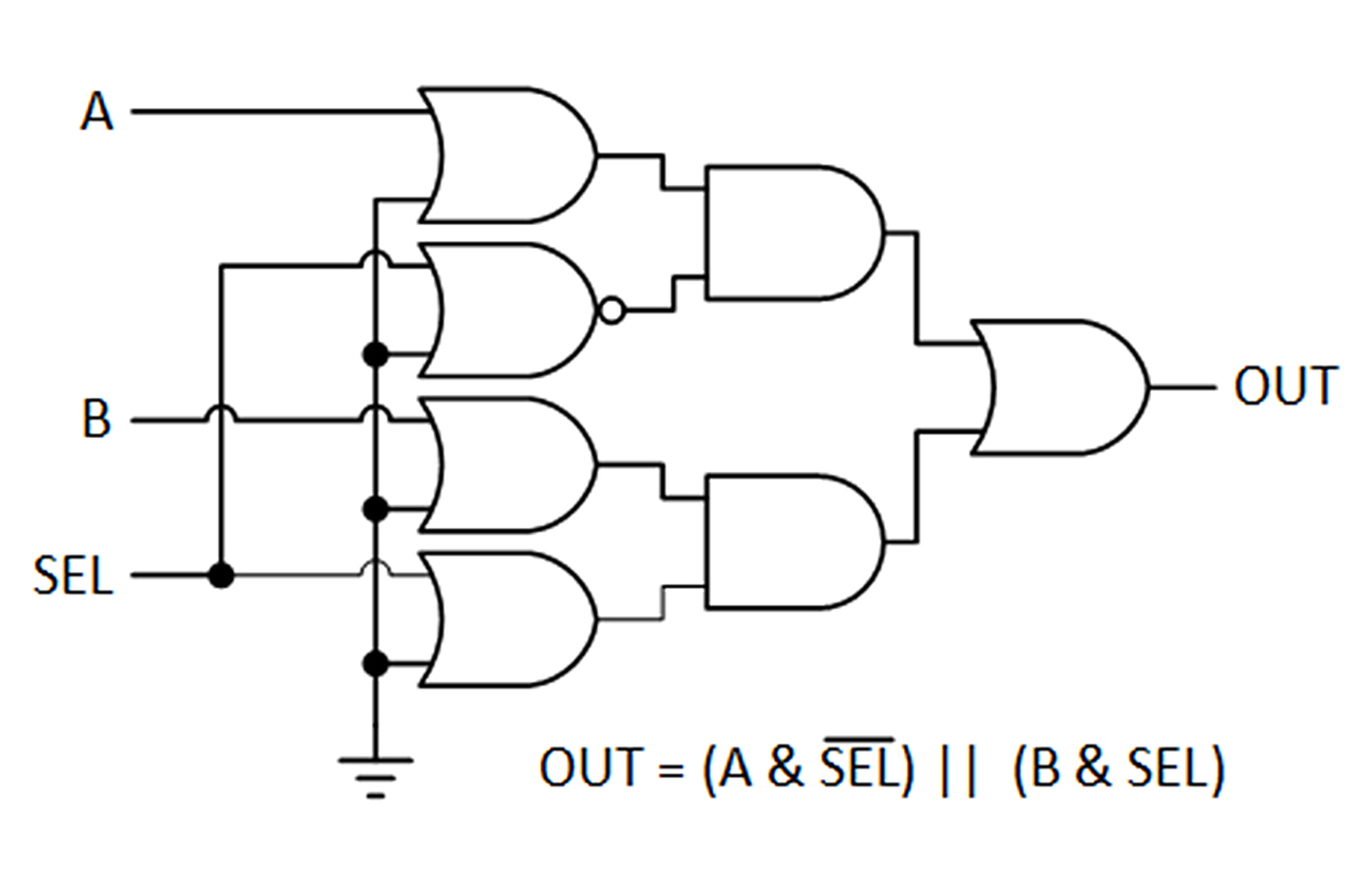
Figura 3. Multiplexor 2:1 implementado en la lógica del CLC; las entradas no utilizadas están ocultas.
Una ventaja de esta implementación respecto a PPS es su velocidad y flexibilidad. PPS se puede bloquear para evitar cambios accidentales en el tiempo de ejecución. Además se puede establecer un bit de configuración para asegurar que PPS solo se pueda desbloquear una vez. En cambio, la configuración del multiplexor CLC permite que el programa cambie las entradas sin pasar cada vez por una secuencia de desbloqueo. Esto se aplica en la demostración de código Morse para la familia PIC18F56Q71 de Microchip. La demostración crea un sencillo transmisor y receptor de código Morse; el multiplexor se usa para seleccionar entre la salida del transmisor y una señal de entrada externa para la recepción.
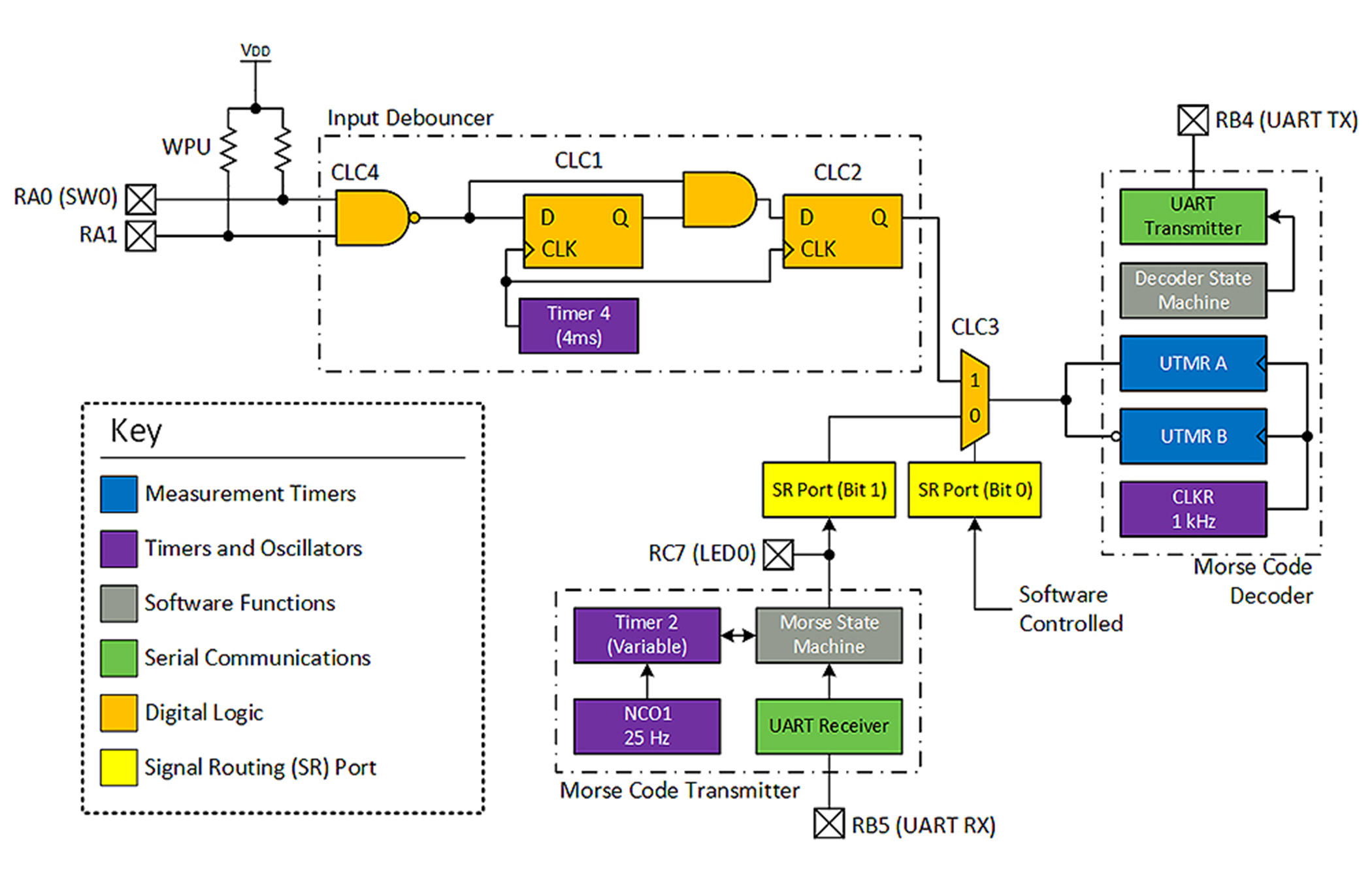
Figura 4. Diagrama de bloques de la demostración de código Morse.
En el programa se definen macros para fijar, borrar y cambiar con un solo bit en las patillas del puerto SR para facilitar su lectura.
//Select input to decoder
#define SELECT_TX_DECODE() do { RW0_SetLow(); } while(0)
#define SELECT_USER_DECODE() do { RW0_SetHigh(); } while(0)
#define SWITCH_DECODE_SOURCE() do { RW0_Toggle(); } while(0)
Este fragmento de código se encarga de la conmutación entre fuentes de entrada. Cuando el transmisor y el receptor están en reposo, y el usuario ha enviado una “#” al terminal, conmutará las fuentes de entrada.
if (morseTx_isSwitchRequested() && morseRx_isIdle() && morseTx_isIdle())
{
//Request to switch input sources
SWITCH_DECODE_SOURCE();
morseTx_clearSwitchRequest();
if (IS_USER_INPUT_ACTIVE())
{
//User Input
printf(«User input is now active.\r\n»);
}
else
{
//TX Input
printf(«Transmitter input is now active.\r\n»);
}
}
El código fuente de este programa está disponible en Github.
Cálculo de paridad acelerado por hardware
En algunos casos es necesario generar un bit de paridad para la transmisión o comunicación de datos. Calcular la paridad con software es fácil, pero su ejecución es más lenta que con hardware. A continuación se muestra una función sencilla.
Nota: El patrón de prueba evaluado se almacena globalmente para estos ejemplos sencillos.
bool isOdd_SW(void)
{
bool isOdd = false;
uint8_t temp;
//Byte Scan
for (uint8_t byIndex = 0; byIndex < DATA_SCAN_LENGTH; byIndex++)
{
//Bit Scan
temp = data[byIndex];
for (uint8_t biIndex = 0; biIndex != 8; biIndex++)
{
if (temp & 0b1)
{
//Count
isOdd = !isOdd;
}
//Shift bits
temp >>= 1;
}
}
return (isOdd);
}
Para acelerar el proceso de puede utilizar un periférico SPI con un CLC para obtener una calculadora de paridad de hardware. El hardware SPI contiene un registro de desplazamiento en serie para transmitir y recibir datos. La salida del hardware SPI (el registro de desplazamiento) se puede introducir en un CLC para crear una calculadora de paridad que funciona a una velocidad notablemente más rápida que la versión de software.
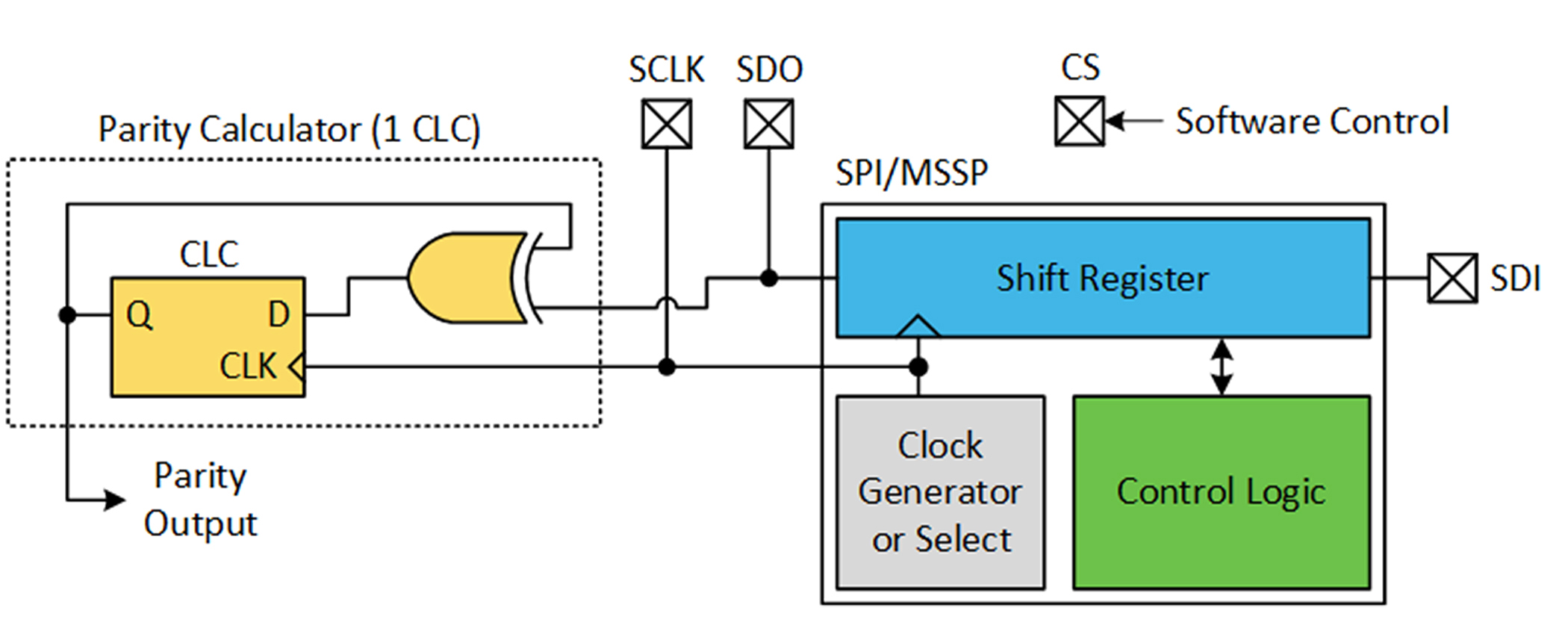
Figura 5. Solución de hardware.
Esta solución también puede reutilizar un periférico SPI existente, disminuyendo así aún más los costes. Esto se debe a que normalmente la línea CS (Chip Select) se debe reclamar a la comunicación con otros dispositivos SPI; pero, si no se reclama, la comunicación es ignorada.
Para obtener la versión acelerada de hardware, primero se capta el actual valor bloqueado en el CLC. Luego se transmiten los datos para calcular la paridad cuando se vuelve a reclamar CS. A continuación se consulta el nuevo valor bloqueado en el CLC. Si el nuevo valor es igual al valor anterior se cuenta un número par de unos. Si los valores difieren, habrá un número impar. Este es el software para calcular una paridad impar:
bool isOdd_HW(void)
{
bool initialState = CLC3_OutputStatusGet();
SPI1_BufferWrite(&data[0], DATA_SCAN_LENGTH);
return (!(CLC3_OutputStatusGet() == initialState));
}
Para demostrar su mayor velocidad se elaboró un pequeño programa de demostración destinado a la familia de microcontroladores PIC16F18146 de Microchip. Uno de los temporizadores internos (Timer 1) se utiliza para contar el número de ciclos de reloj (FOSC/4) necesarios para ejecutar los cálculos de paridad con hardware y software. Los resultados se imprimieron en un terminal serie para analizarlos. A continuación se muestra una copia de los resultados obtenidos para diferentes niveles de optimización del compilador.
| Nivel de optimización | Tiempo con software | Tiempo con hardware | Diferencia (%) |
| Nivel 0 (Ninguno) | 1726 | 552 | +313% |
| Nivel 1 | 1371 | 533 | +257% |
| Nivel 2 | 1371 | 533 | +257% |
| Nivel 3 (Velocidad) | 1019 | 465 | +219% |
| Nivel S (Tamaño) | 1019 | 465 | +219% |
Tabla 1. Diferencias de rendimiento entre las soluciones de software y hardware, secuencia de 10 bytes.
La mejora de rendimiento mostrada en este ejemplo depende de las velocidades del reloj del microcontrolador y del periférico SPI. El código fuente de este programa está disponible en Github.
Conclusiones
Los periféricos de hardware son una función importante en los sistemas embebidos. Gracias a ellos, los microcontroladores pueden ser más potentes, eficientes y capacitados. Los periféricos de lógica y flexibilidad son herramientas especialmente potentes para gestionar tareas sencillas como la eliminación de rebote o la decodificación de cuadratura. El uso creative de los periféricos de hardware mejora los diseños y eleva el listón de lo que es posible conseguir con un microcontrolador.





