Implementación de aplicaciones aceleradas de aprendizaje automático con un microcontrolador avanzado
La inteligencia artificial (Artificial Intelligence, AI) ha sido históricamente una tecnología dependiente de una GPU / CPU o incluso un DSP. Sin embargo, la AI ha evolucionado en los últimos tiempos hacia sistemas de adquisición de datos por medio de la integración en aplicaciones de menor tamaño ejecutadas en microcontroladores más pequeños. Esta tendencia viene impulsada sobre sobre todo por el mercado IoT (Internet de las Cosas), en el que Silicon Labs juega un importante papel.
Para abordar esta nueva tendencia de IoT, Silicon Labs ha anunciado un microcontrolador inalámbrico que puede realizar operaciones de AI aceleradas por hardware. Para conseguirlo, este microcontrolador se ha diseñado de tal manera que integra un procesador MVP (Matrix Vector Processor) denominado EFR32xG24.
Este artículo ofrece en primer lugar una introducción a la AI en la que se exponen algunos ejemplos prácticos a los que se destina el MVP. Y por encima de todo, cómo usar el EFR32xG24 para diseñar una aplicación AI IoT.
Aspectos básicos sobre inteligencia artificial, aprendizaje automático e informática de borde
AI es un sistema que intenta imitar el comportamiento humano. Se trata en concreto de una entidad eléctrica y/o mecánica que imita una respuesta a un estímulo de modo similar al de una persona. Aunque los términos IA y aprendizaje automático (Machine Learning, ML) a menudo se utilizan indistintamente, ambos representan dos metodologías diferentes. IA es un concepto más amplio, mientras que ML es un subconjunto de AI.
El ML permite a un sistema elaborar predicciones y mejorar (o entrenarse) tras el uso repetitivo de lo que se denomina un modelo. Un modelo es el uso de un algoritmo entrenado que en última instancia se utiliza para emular la toma de decisiones. Este modelo puede ser entrenado recogiendo datos o aprovechando conjuntos de datos existentes. Cuando el sistema aplica su modelo “entrenado” a nuevos datos adquiridos para tomar decisiones nos referimos a él como Inferencia de Aprendizaje Automático.
Como se ha señalado antes, la inferencia requiere una potencia de cálculo que solía ser proporcionada por ordenadores de gama alta. No obstante, ahora estamos en condiciones de ejecutar la inferencia en dispositivos más pequeños que no necesitan estar conectados a esos sistemas de gama alta: se denomina Edge Computing o informática de borde.
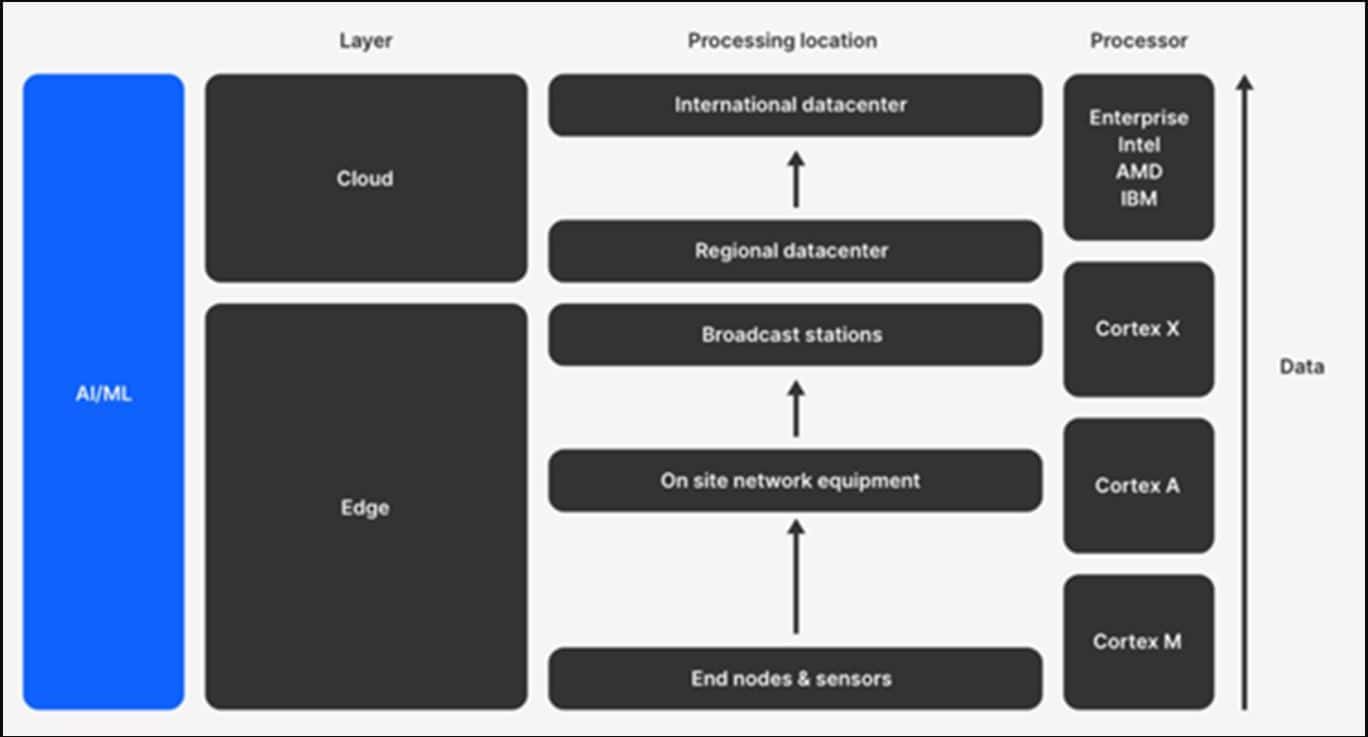
La ejecución de la inferencia en un microcontrolador se considera informática de borde, que consiste en ejecutar algoritmos de procesamiento de datos en el punto más cercano al lugar en el que se adquirieron esos datos. Los dispositivos de borde suelen ser sencillos y de pequeño tamaño, como sensores o actuadores básicos (bombillas, termostatos, sensores de puerta o contadores de electricidad). Estos dispositivos suelen ser microcontroladores de tipo ARM Cortex-M con un bajo consumo:
La informática de borde ofrece muchas ventajas, la mayor de las cuales es probablemente que el sistema la aprovecha para no depender de una entidad externa. Los dispositivos pueden “tomar sus propias decisiones” localmente.
Tomar decisiones localmente ofrece las siguientes ventajas prácticas:
Disminuye la latencia
Los datos en bruto no se han de transferir a la nube para su procesamiento, lo cual significa que las decisiones pueden aparecer en tiempo real en el dispositivo.
Reduce el ancho de banda de internet necesario
Los sensores generan una enorme cantidad de datos en tiempo real que a su vez crean una gran demanda de ancho de banda incluso si no hay nada que “informar”; esto satura el espectro inalámbrico y aumenta el coste de ejecución.
Reduce el consumo
Su consumo es considerablemente menor al analizar datos localmente (con AI) que para transmitir los datos.
Permite cumplir los requisitos de privacidad y seguridad
Tomar las decisiones localmente evita el envío de datos en bruto detallados a la nube, sino solo resultados de inferencia y metadatos, eliminando así el riesgo potencial de brechas de privacidad de los datos.
Reduce el coste
Analizar los datos del sensor localmente evita recurrir a la infraestructura de la nube y el tráfico.
Aumenta la resiliencia
En el caso de que falle la conexión a la nube, el nodo del borde podrá seguir funcionando de manera autónoma.
EFR32xG24 de Silicon Labs para informática de borde
EFR32xG24 es un microcontrolador inalámbrico seguro que admite varios protocolos IoT de 2,4 GHz (Bluetooth Low Energy, Matter, Zigbee y protocolos OpenThread). También incluye Secure Vault, un paquete de funciones de seguridad avanzada común a todas las plataformas Silicon Labs Series 2.
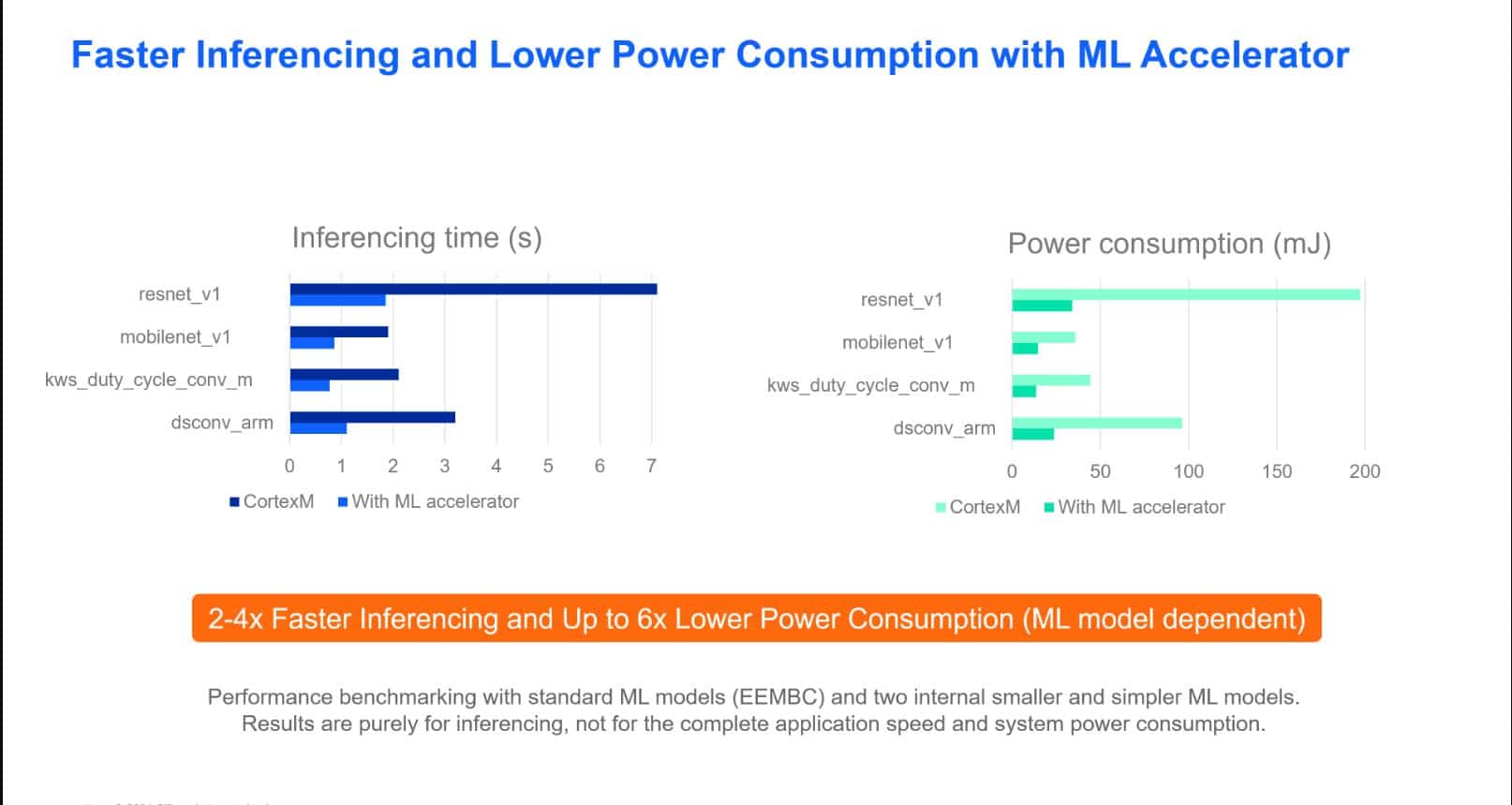
Además de unos niveles de seguridad y conectividad exclusivos en este microcontrolador hay un Acelerador de Hardware para Inferencia de modelos ML (entre otras aceleraciones) llamado Matrix Vector Processor (MVP).
El MVP ofrece la capacidad de ejecutar inferencias de ML más eficientemente, con un consumo hasta 6 veces más bajo y una velocidad entre 2-4 veces mayor si se compara con ARM Cortex-M sin aceleración de hardware (la mejora real depende del modelo y de la aplicación).
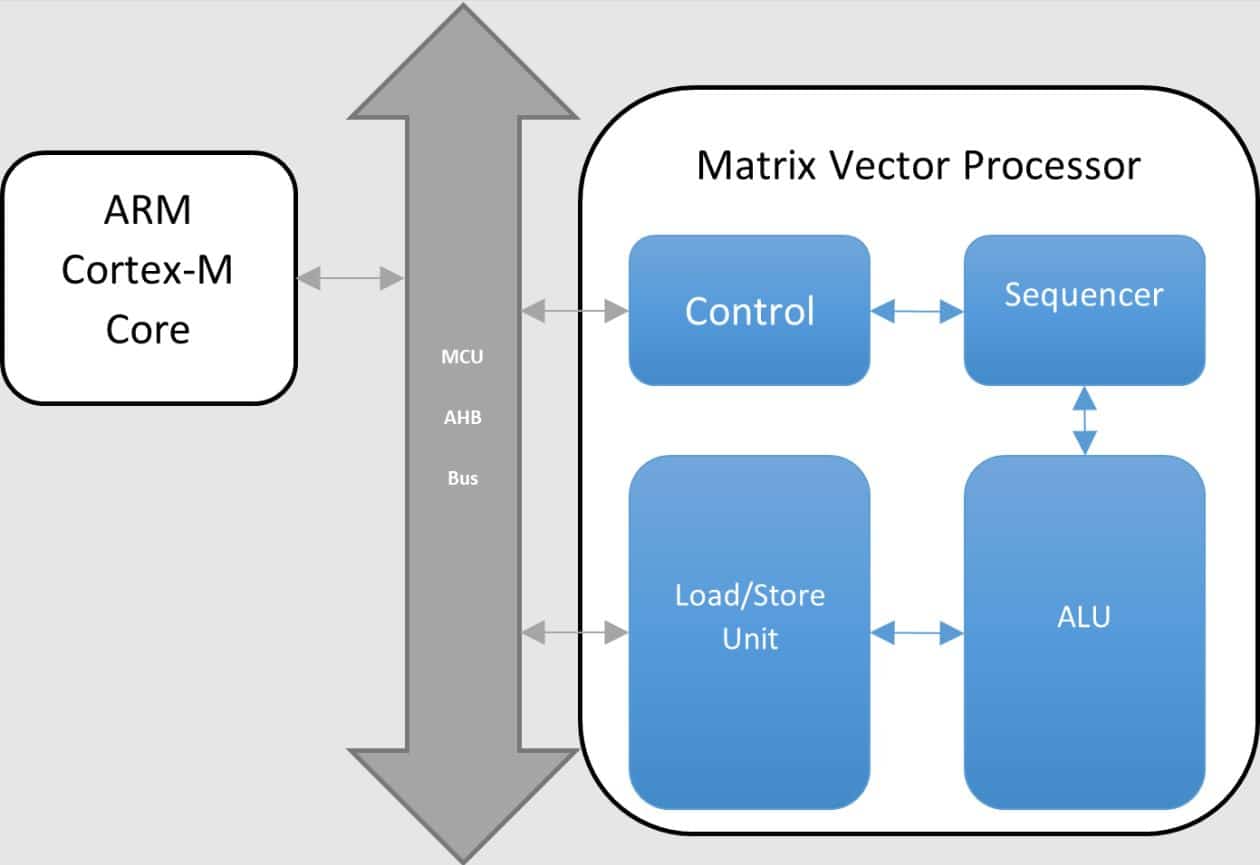
El MVP está diseñado para liberar a la CPU realizando operaciones intensivas de coma flotante. Está especialmente diseñado para multiplicaciones y sumas complejas de matrices con coma flotante.
El MVP está constituido por una unidad lógica aritmética (arithmetic logic unit, ALU), una unidad de carga/almacenamiento (load/store unit, LSU) y un secuenciador.
Como resultado de ello, el MVP ayuda a acelerar el procesamiento y a disminuir el consumo en una gran variedad de aplicaciones, como Ángulo de Llegada (Angle-of-Arrival, AoA), procesamiento de algoritmos MUSIC y ML (Eigen o BLAS – Basic Linear Algebra Subprograms), entre otras.
Dado que este dispositivo es un simple microcontrolador, no puede asumir todas las funciones que podrían cubrir IA/ML. Está diseñado para las cuatro categorías siguientes, que aparecen citadas junto a aplicaciones de la vida real:
Procesamiento de la señal del sensor
Mantenimiento predictivo
Análisis de señales biológicas
Monitorización de la cadena de frío
Aplicaciones con acelerómetros
Correspondencia entre patrones de audio
Detección de cristales rotos
Detección de disparos
Instrucciones por voz
Palabras de control para electrodomésticos inteligentes
Detección de palabras de activación
Visión a baja resolución
Detección de presencia
Conteo
Huellas dactilares
Para ello, Silicon Labs suministra aplicaciones de muestra basadas en un entorno AI/ML llamado TensorFlow.
TensorFlow es una plataforma de código abierto de extremo a extremo para aprendizaje automático de Google. Incorpora un sistema completo y flexible formado por herramientas, bibliotecas y recursos de la comunidad que permite a los investigadores estar a la vanguardia de ML y facilita a los desarrolladores el diseño y la implementación de aplicaciones ML.
El proyecto de TensorFlow cuenta con una versión optimizada de hardware embebido denominada TensorFlow Lite for Microcontrollers (TFLM). Se trata de un proyecto de código abierto en el que la mayor parte del código es aportado por ingenieros de la comunidad, incluidos Silicon Labs y otros proveedores de dispositivos de silicio. Por el momento es el único entorno suministrado junto a Silicon Labs Gecko SDK Software Suite para crear aplicaciones AI/ML.
Estos son algunos ejemplos de AI/ML de Silicon Labs:
Interruptor de luz Zigbee 3.0 activado por voz
Tensor Flow Magic Wand
LED activado por voz
Tensor Flow Hello world
Tensor Flow Micro speech
Para empezar a desarrollar una aplicación basada en alguno de ellos se puede tener muy poca experiencia o ser un experto. Silicon Labs proporciona diversas herramientas de desarrollo para ML entre las cuales escoger dependiendo de su nivel de conocimientos sobre ML.
Los desarrolladores sin experiencia en ML pueden tomar como punto de partida uno de nuestros ejemplos o probar con una de nuestras empresas colaboradoras. Estas empresas especializadas en ML ofrecen soporte a todo el flujo de trabajo a través de interfaces gráficas con numerosas funciones y fáciles de usar destinadas al desarrollo del modelo óptimo de ML para nuestros chips.
Para los expertos en ML que deseen trabajar directamente con la plataforma Keras/TensorFlow, Silicon Labs ofrece un paquete de referencia de autoservicio y autoasistencia que organiza el flujo de trabajo para el desarrollo del modelo hacia la construcción de modelos ML para chips de Silicon Labs.
Desarrollo de un ejemplo de aplicación con ML: interruptor Zigbee controlado por voz con EFR32xG24
Para crear una aplicación con ML es necesario dar dos pasos principales. El primero consiste en crear una aplicación inalámbrica, lo cual se puede hacer con Zigbee, BLE, Matter o cualquier aplicación basada en un protocolo propietario de 2,4 GHz. Puede ser incluso una aplicación no conectada. El segundo paso es construir un modelo ML para integrarlo en la aplicación.
Como se ha dicho antes, Silicon Labs ofrece varias opciones con el objetivo de crear una aplicación ML para sus microcontroladores. La opción escogida en este caso consiste en utilizar una aplicación de muestra existente con un modelo predefinido. En este ejemplo, el modelo es entrenado para detectar dos instrucciones de voz: “on” y “off”.
Primeros pasos con una aplicación basada en EFR32xG24
En primer lugar, adquiera el kit para desarrollador con EFR32MG24:
el BRD2601A (izq.).
Este kit de desarrollo es una pequeña tarjeta que incorpora varios sensores (inercial, temperatura y humedad relativa, entre otros), LED y micrófonos I2S estéreo.
Este proyecto usará micrófonos I2S.
Estos dispositivos podrían no ser tan poco comunes como las GPU, pero si no tiene la posibilidad de adquirir uno de estos kits, también puede recurrir a un kit de desarrollo más antiguo de la Serie 1 denominado “Thunderboard Sense 2” Ref. SLTB004A (dcha.).
No obstante, este microcontrolador no incorpora un MVP y realizará toda la inferencia recurriendo al núcleo principal sin aceleración.
A continuación necesita Simplicity Studio, el IDE de Silicon Labs, para crear el proyecto ML. Se suministra para facilitar la descarga de Gecko SDK Software Suite de Silicon Labs, que proporciona las bibliotecas y los drivers que necesite la aplicación, tal como sigue.
La pila de red inalámbrica (Zigbee en este caso)
Los drivers de hardware (para micrófonos I2S y para el MVP)
El entorno TensorFlow Lite
Un modelo ya entrenado para detectar palabras de control
El IDE también proporciona herramientas destinadas a analizar el consumo de su aplicación o las operaciones a través de la red.
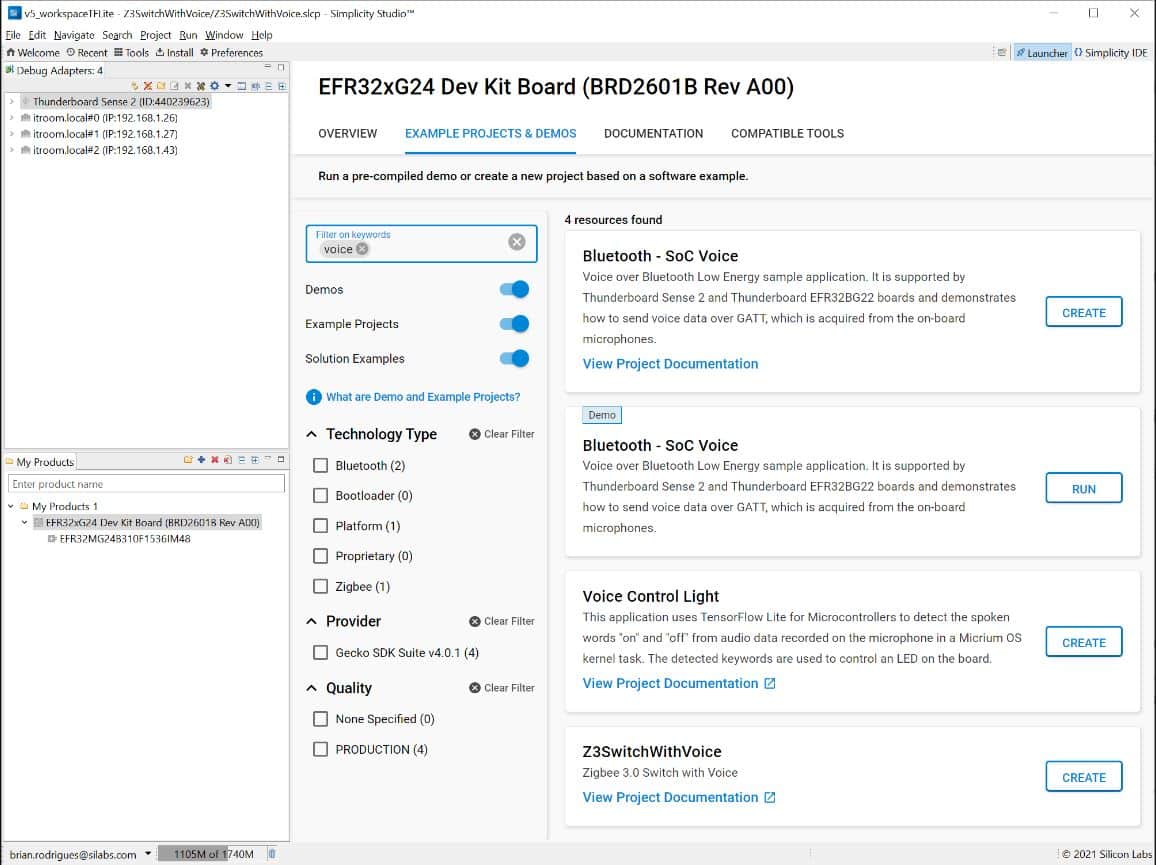
Creación del proyecto de interruptor Zigbee 3.0 con MVP
Silicon Labs suministra una aplicación de muestra lista para usar, Z3SwitchWithVoice, que ya incorpora un modelo ML por lo que no es necesario crear uno.
Una vez creado, obsérvese que un proyecto Simplicity Studio está formado por archivos fuente aportados por componentes que son entidades GUI que recurren a los microcontroladores de Silicon Labs y simplifican la integración de software complejo. En este caso se puede ver que el soporte para MVP y la pila de red Zigbee se ha instalado por defecto.
El código de aplicación principal está en el archivo fuente app.c.
En la parte de la red, la aplicación se puede vincular a cualquier red Zigbee 3.0 existente con solo pulsar un botón, también denominado “network steering” o manejo de red. Una vez en la red, el microcontrolador buscará un dispositivo de iluminación compatible y vinculable.
Cuando ya está en funcionamiento la parte de la red de la aplicación, el microcontrolador consultará periódicamente muestras de los datos del micrófono y ejecutará la inferencia en él. Este código se encuentra en keyword_detection.c.
sl_zigbee_app_debug_print(«%s: 0x%02X\n», «Send to bindings», status);
}
}
En este punto ya disponemos de una inferencia acelerada de hardware ejecutándose en un microcontrolador inalámbrico para informática de borde.
Personalización del modelo TensorFlow para usar diferentes palabras de control
Como se ha mencionado antes, el modelo real ya estaba integrado en la aplicación y no se modificó después. No obstante, si usted mismo integrada el modelo lo haría siguiendo estos pasos:
Recoger y etiquetar los datos
Diseñar y construir el modelo
Evaluar y comprobar el modelo
Convertir el modelo para el dispositivo embebido
Estos pasos se deben seguir con independencia de cuál sea el grado de conocimientos sobre ML. La diferencia reside en cómo construir el modelo:
Si usted es un principiante en ML, Silicon Labs recomienda usar una de nuestras plataformas fáciles de usar suministradas por empresas colaboradoras, Edge Impulse o SensiML, para construir su modelo.
Su usted es un experto en Keras/TensorFlow y no desea utilizar herramientas de terceros puede recurrir a Machine Learning Tool Kit (MLTK), un paquete de python de autoservicio y autoasistencia. Silicon Labs ha creado este paquete de referencia destinado a audio y se puede ampliar, modificar o adaptar por piezas que elija el experto. Este paquete estará disponible en GitHub junto con su documentación. También se puede importar directamente un archivo .tflite que se ejecuta en una versión embebida de TensorFlow lite para microcontroladores compilada para la línea de productos EFR32. Es preciso asegurarse de que la función de extracción de los datos es EXACTAMENTE la misma para entrenar el modelo de lo que sería para ejecutar la inferencia en el chip objetivo.
Esta última parte es la más sencilla en Simplicity Studio. Para cambiar el modelo en Simplicity Studio, copie el archivo de su modelo .tflite en la carpeta config/tflite de su proyecto. El configurador del proyecto proporciona una herramienta que convertirá automáticamente los archivos .tflite en una fuente sl_ml_model y archivos de encabezado. Toda la documentación para esta herramienta se encuentra disponible en Flatbuffer Conversion.
[Nota: Todas las imágenes y el código son cortesía de Silicon Labs.]
Utilizamos cookies para optimizar nuestro sitio web y nuestro servicio.
Funcional
Siempre activo
El almacenamiento o acceso técnico es estrictamente necesario para el propósito legítimo de permitir el uso de un servicio específico explícitamente solicitado por el abonado o usuario, o con el único propósito de llevar a cabo la transmisión de una comunicación a través de una red de comunicaciones electrónicas.
Preferencias
El almacenamiento o acceso técnico es necesario para la finalidad legítima de almacenar preferencias no solicitadas por el abonado o usuario.
Estadísticas
El almacenamiento o acceso técnico que es utilizado exclusivamente con fines estadísticos.El almacenamiento o acceso técnico que se utiliza exclusivamente con fines estadísticos anónimos. Sin un requerimiento, el cumplimiento voluntario por parte de tu Proveedor de servicios de Internet, o los registros adicionales de un tercero, la información almacenada o recuperada sólo para este propósito no se puede utilizar para identificarte.
Marketing
El almacenamiento o acceso técnico es necesario para crear perfiles de usuario para enviar publicidad, o para rastrear al usuario en una web o en varias web con fines de marketing similares.